并发编程是指在一台处理器上“同时”处理多个任务。
多线程就是用来实现并发编程
多线程可以理解为多个异步的代码
线程就是为了实现代码的异步执行
如果开启了多线程,就是多个线程几乎同时开始执行
线程的使用场景:
- 如果两个任务需要内存的共享,且想实现异步,那么就使用多线程
- 高IO类型的程序(爬虫 网页编程 socket)一般都会使用多线程
- 在日常开发中我们会使用线程比较多,因为线程的运行会比进程的快,还有 CPU 在线程之间切换 比 在进程之间切换要快,且进程一般都是用在计算类型的程序(只是做算数用的程序)中
开多线程,线程数超过3个以上就使用线程池来处理
threading 模块 -> 综合的管理线程的包
所有创建线程的程序都无需放在 if __name__ == '__main__' 下执行了,如果为了容易分别那个是主线程或者子线程也是可以使用的
threading 线程模块的用法 和 multiprocessing 进程模块差不多
一个 py 文件就相当于一个进程了,所以可以直接在 py 文件下直接创建线程,这样就可以解释线程一定是存在进程中的
多个线程使用同一个进程的数据(一个进程中的多个线程是可以直接使用这个进程中的数据 -> 类似于多个进程可以调用同一个数据一样)
1. Thread 类 -> 用于创建线程
- Thread(target=函数名, args=函数接收的参数) -> args 必须接收一个元组
import time
from threading import Thread
# 子线程
def fun():
time.sleep(1)
print('hello')
# 主线程
t = Thread(target=fun) # 创建一个线程执行一个函数
t.start() # 开启线程
print('---- 主线程 ----') # 当线程启动后 t.start() 下方的代码不会等待线程所绑定的函数执行完再开始执行,而是直接往下执行,因为此时线程所绑定的函数已经变成了异步代码了
# 执行结果:
# -------主线程-------
# hello

- .join() -> 主线程的代码会在 .json() 这里进行阻塞,等待子线程(线程所绑定的函数)执行完后,才会往下执行 -> 当使用了.join(),程序就会变成同步执行了
import time
from threading import Thread
# 子线程
def fun():
time.sleep(1)
print('hello')
# 主线程
t = Thread(target=fun)
t.start()
t.join() # 阻塞 -> 等待子线程(线程所绑定的函数)执行完后,才会往下执行
print('---- 主线程 ----')
# 执行结果:
# hello
# -------主线程-------
- 开启多个子线程
# 同时开启20个线程执行 fun 函数
import time
import os
from threading import Thread
# 子线程
def fun(i):
time.sleep(1)
print('%s.线程' % i, os.getpid())
# 主线程
t_l = []
for i in range(20):
t = Thread(target=fun, args=(i,)) # 同时开启20个线程执行 fun 函数
t.start() # 开启线程
t_l.append(t)
[i.join() for i in t_l] # 等待所有线程结束后再执行下方代码
print('-----主线程-----', os.getpid())
2.线程函数调用外部的变量和函数的注意事项
- 从线程的角度说明: 因为一个进程中的多个线程是可以直接使用这个进程中的数据,且一个py文件就相当于一个进程
- 不按照线程的说法: 函数本来就可以调用外部的变量和方法,因为作用域链
- 如果要调用的变量和函数在 if __name__ == '__main__': 里面必须用传参的形式调用不然就会报错,因为线程函数无法直接调用 if __name__ == '__main__': 里面的方法和函数,如果是直接执行该函数是可以的,但是如果是被线程执行就不行
from threading import Thread
def fun(if_data):
print(data) # 获取进程中的数据 -> 直接调用线程函数外部的并且不在 if __name__ == '__main__': 里面的变量,函数是可以直接调用函数外部的变量或方法(因为作用域链)
print(if_data) # 获取进程中的数据 -> 使用传参的形式调用 if __name__ == '__main__': 里面的变量
f() # 直接调用线程函数外部的并且不在 if __name__ == '__main__': 里面的方法,函数是可以直接调用函数外部的变量或方法(因为作用域链)
print('子线程')
data = '这是进程中的数据'
def f():
print('这是进程中的函数')
if __name__ == '__main__': # 线程的定义可以不用放在 if __name__ == '__main__': 里面执行,但是如果放在了 if main 里面那么就要注意线程函数调用外部变量和函数的注意事项了
if_data = 'if_main里面的参数'
t = Thread(target=fun, args=(if_data,))
t.start()
t.join()
print('----主线程----')
3. 创建线程的方法二 -> 通过继承方式
import time
import os
from threading import Thread
class MyThread(Thread): # 通过继承 Thread 类,从而创建一个线程
def __init__(self, d1, d2):
super().__init__()
self.d1 = d1
self.d2 = d2
def run(self): # run 方法就相当于线程所绑定的函数
t_name = self.name # 获取线程的名字
t_id = self.ident # 获取线程的id
print(self.d1, self.d2, t_name, t_id)
t = MyThread('数据一', '数据二') # 创建一个线程
t.start() # 当线程启动的时候就会调用类中的 run 方法
t.join()
print('----主线程----')
# 例子计算开启了多少个线程数量
# 使用静态属性计算线程被调用了多少次,从而实现多个线程共享(使用)一个数据
import time
import os
from threading import Thread
class MyThread(Thread): # 通过继承 Thread 类,从而创建一个线程
count = 0 # 通过静态属性计算线程被调用了多少次
def __init__(self, d1, d2):
super().__init__()
self.d1 = d1
self.d2 = d2
def run(self): # run 方法就相当于线程所绑定的函数
MyThread.count += 1
time.sleep(1)
print(self.d1, self.d2)
t_l = []
for i in range(10):
t = MyThread('数据一', '数据二') # 创建一个线程
t.start() # 当线程启动的时候就会调用类中的 run 方法
t_l.append(t)
[i.join() for i in t_l] # 等待所有的线程结束后再往下执行
print('线程被调用了:%s 次' % t.count)
4.threading.currentThread() -> 获取当前线程的一些信息
import threading
import time
def fun(i):
time.sleep(0.5)
t_name = threading.currentThread().name # 线程的名字
t_id = threading.currentThread().ident # 线程的id
print('线程名字:%s' % t_name)
print('线程id:%s' % t_id)
for i in range(10):
t = threading.Thread(target=fun, args=(i,))
t.start()
print(threading.enumerate()) # 返回正在运行的线程列表
print(threading.activeCount()) # 返回正在运行的线程总数 -> 线程数永远都是你开的线程数 + 1,因为主线程也算一个线程
5.守护线程
- 守护线程会随着主线程的代码执行结束而结束,不会等待其他子线程
- .setDaemon(True) 开启守护线程,且一定要设置在 start 之前
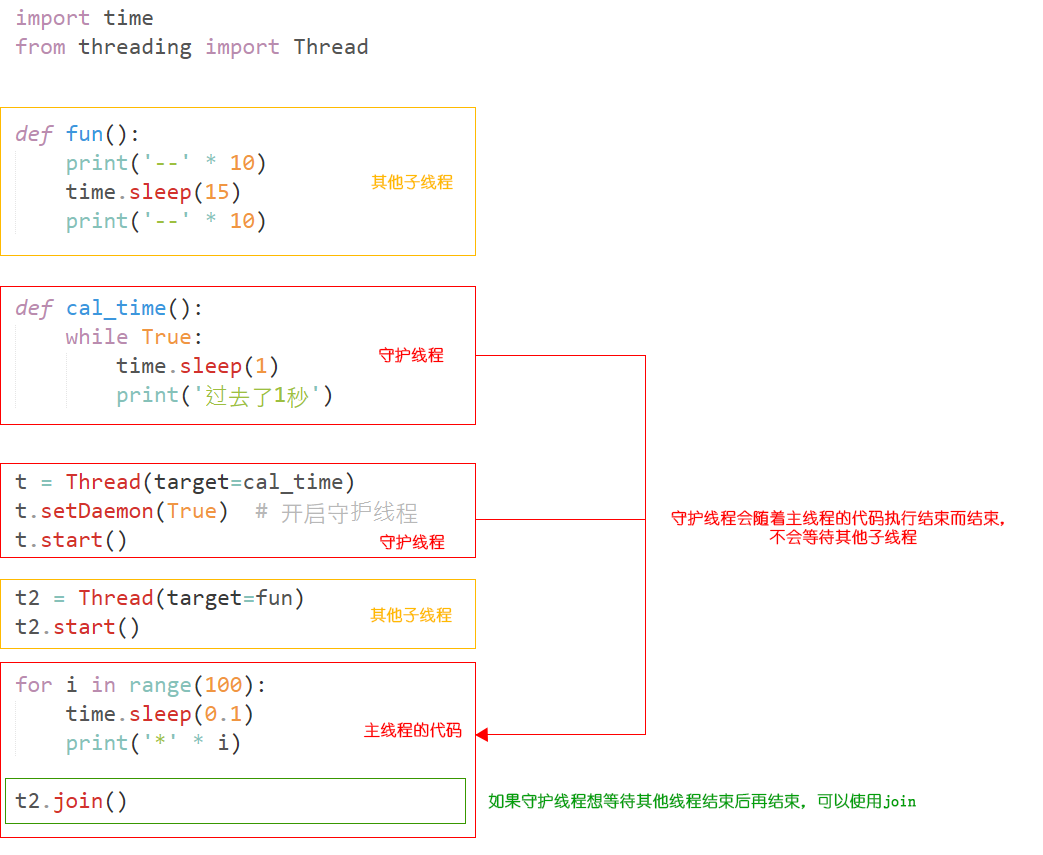
# 报时器例子: 每个1秒就会报一次时
# 开启了守护线程 -> cal_time 会随着主线程的代码执行结束而结束
import time
from threading import Thread
def cal_time():
while True:
time.sleep(1)
print('过去了1秒')
t = Thread(target=cal_time)
t.setDaemon(True) # 开启守护线程,一定要设置在 start 之前
t.start()
for i in range(100):
time.sleep(0.1)
print('*' * i)
# 报时器例子: 每个1秒就会报一次时
# 没有开启守护线程 -> cal_time子线程会一直执行
import time
from threading import Thread
def cal_time():
while True:
time.sleep(1)
print('过去了1秒')
t = Thread(target=cal_time)
t.start()
for i in range(100):
time.sleep(0.1)
print('*' * i)
# 上面图片的代码
import time
from threading import Thread
# 守护线程
def cal_time():
while True:
time.sleep(1)
print('过去了1秒')
# 其他子线程
def fun():
print('--' * 10)
time.sleep(15)
print('--' * 10)
# 守护线程
t = Thread(target=cal_time)
t.setDaemon(True) # 开启守护线程
t.start()
# 其他子线程
t2 = Thread(target=fun)
t2.start()
# 主线程代码
for i in range(100):
time.sleep(0.1)
print('*' * i)
t2.join() # 如果守护线程想等待其他线程结束后再结束,可以使用join
6. 多线程的应用
- 创建多个线程实现TCP协议多人聊天 -> 因为每个线程之间是独立的所以可以实现TCP协议的多人通讯
# server.py
import socket
from threading import Thread
def fun(conn):
conn.send(b'hello')
print(conn.recv(1024).decode('utf-8'))
sk = socket.socket()
sk.bind(('127.0.0.1', 8080))
sk.listen()
while True:
conn, addr = sk.accept()
t = Thread(target=fun, args=(conn,))
t.start()
conn.close()
sk.close()
# client.py
import socket
sk = socket.socket()
sk.connect(('127.0.0.1', 8080))
print(sk.recv(1024).decode('utf-8'))
msg = input('>>>')
sk.send(bytes(msg, encoding='utf-8'))
sk.close()